HCMUS at MediaEval 2020: Image-Text Fusion for Automatic News-Images Re-Matching (MediaEval 2020)
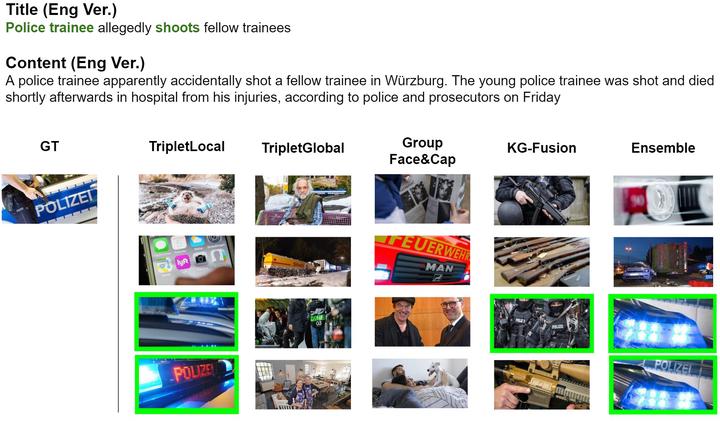 A sample of results from our methods for news-images cross-domain retrieval. Given the inputs of a news title and summary (content), our methods retrieve candidate images that can potentially be used as illustrative covers for the news piece.
A sample of results from our methods for news-images cross-domain retrieval. Given the inputs of a news title and summary (content), our methods retrieve candidate images that can potentially be used as illustrative covers for the news piece.Abstract
Matching text and images based on their semantics has an important role in cross-media retrieval. Especially, in terms of news, text and images connection is highly ambiguous. In the context of MediaEval 2020 Challenge, we propose three multi-modal methods for mapping text and images of news articles to the shared space in order to perform efficient cross-retrieval. Our methods show systemic improvement and validate our hypotheses, while the best-performed method reaches a recall@100 score of 0.2064.
Type
Publication
In Multimedia Benchmark Workshop 2020
We propose three multi-modal methods for mapping text and images of news articles to the shared space in order to perform efficient cross-retrieval.